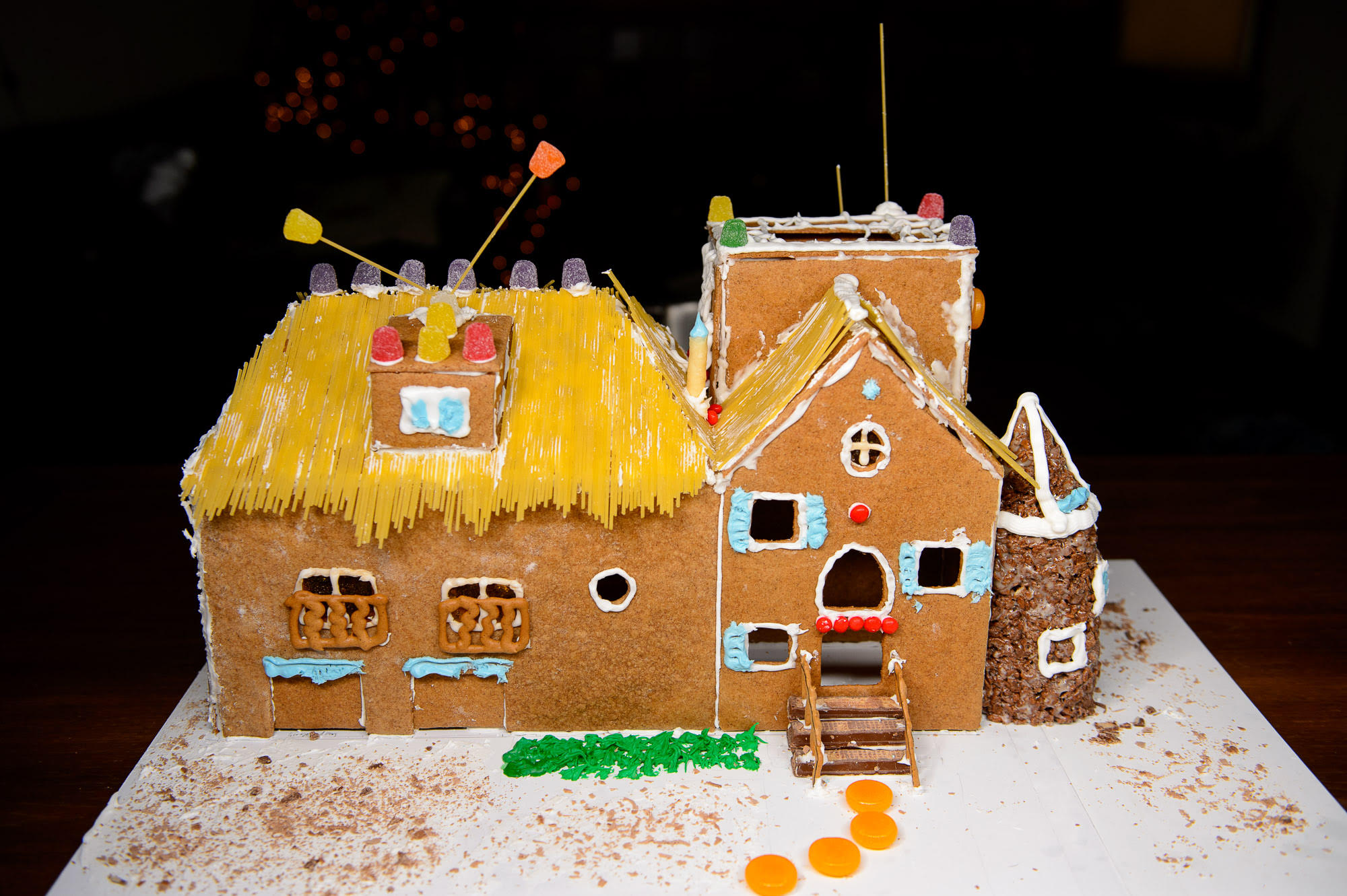
A few different things led me to this contest over winter break. I’ve been feeling sort of unfulfilled creatively for a few years now - engineering school will do that to you, I think. Around Halloween, I saw Stella Parks’ haunted gingerbread house and thought for a second that it’d be a good thing to do before a Halloween party we were throwing, but there just wasn’t time.
A few weeks later, I saw the McMansion Hell contest - it seemed totally perfect, a creative project that I might actually be able to finish. I started thinking of ideas, and ways of keeping myself from burning out halfway through. I’ve left a lot of half-finished projects lying around after losing interest. When I flew home for Christmas, I found a self-help book at the airport called Finish (which I could not be mature about). I brought myself back from the brink of actually buying a self-help book at Hudson News, and started reading Amazon reviews to find the two bits of useful advice in it. I had already been thinking along these lines, so I really latched onto those ideas of cutting my goal in half and trying to reduce perfectionism.
I made a couple of test houses to practice the gingerbread/icing recipes (Stella’s), and they really helped me adjust my expectations of the scale of this project. It turns out even making the style of house that a 5-year-old might draw is super hard. I canned a lot of my original ideas, like having interior rooms or dormers on every roof.
Stella points out a huge advantage to a haunted gingerbread house - any mistakes you make are consistent with the theme. So a broken piece of the facade, hastily glued together with icing, is just one more aspect of a spooky old house. A similar thing happens with a gingerbread McMansion: If it’s lopsided, or shoddily decorated, or the design is just plain ugly, that’s because it’s a cheap house designed by committee and built to be big instead of tasteful.
The project took place over three days, not including the design process, learning about architecture from reading the McMansion Hell blog, or my two practice houses.
Day 1: Cutting templates and baking pieces
I started the morning by making 6 batches of Stella’s construction gingerbread recipe and putting them in the fridge. I ended up doing this in two batches, since I didn’t really think my mom’s old KitchenAid would fit all of the dough.
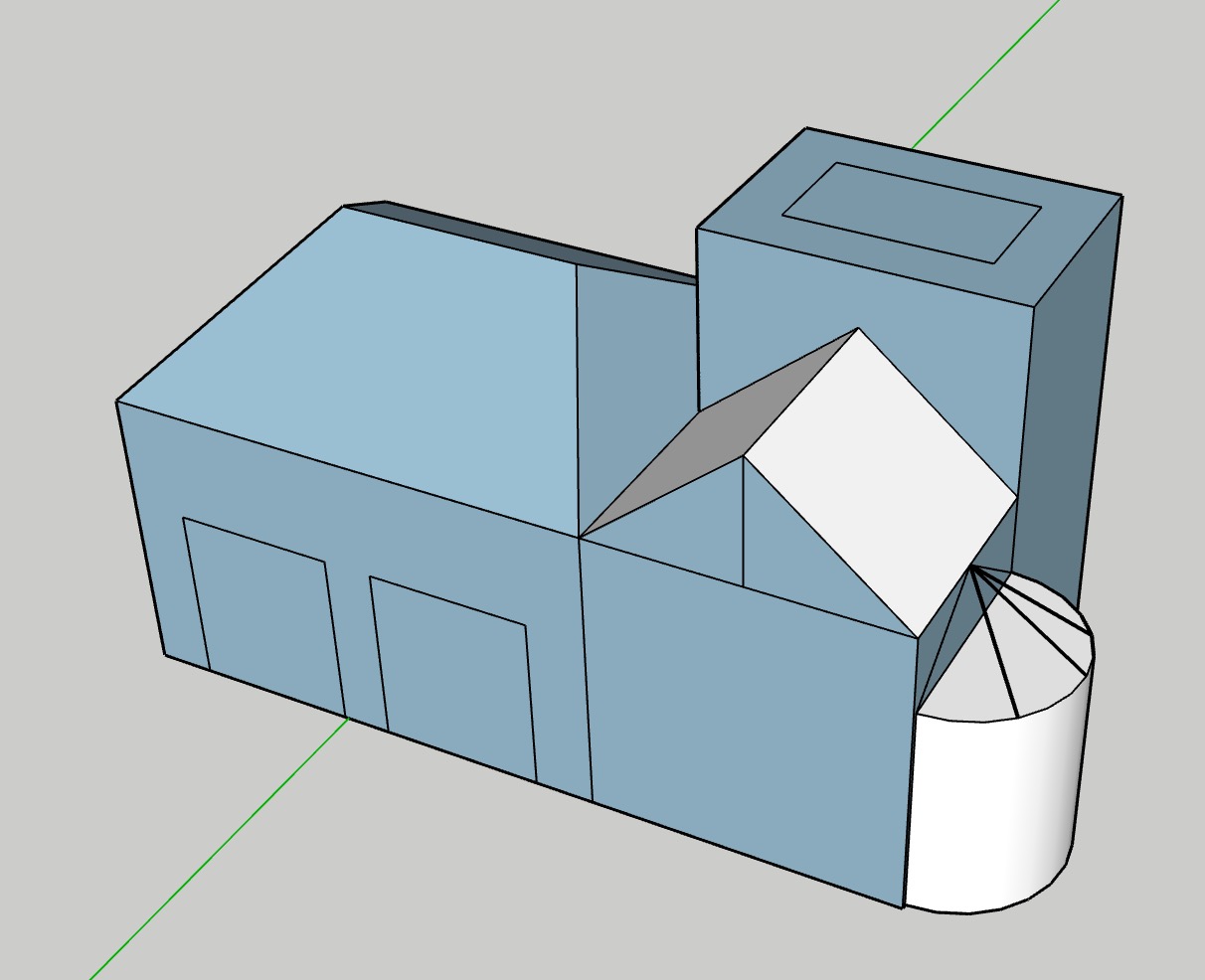
Once this was done, I turned my attention to the template. I drew an excellent model in SketchUp, and planned the measurements. I drew every piece on a big cardboard box, then cut them out (I found a T-square in the basement, which was lifesaving). To make sure all of the measurements were right, I tried putting it all together with packing tape. Pieces that were on the inside of joints got about 1⁄8” cut off of them to account for the thickness of the pieces. The thing seemed to stand up on its own ok, so I was ready to make the gingerbread pieces.
I took a break at that point to finally see Free Solo (so good) and get lunch and a coffee. I always love sitting in diners with some food and coffee, not doing anything besides looking around and listening to people. Even better when there’s a bar to sit at. Eating alone is very underrated.
I had a loose plan for which cardboard pieces would go on which sheet, and mostly stuck to it. This part was pretty mind-numbing. Roll out a sheet, put it on my parents’ one sheet pan (my sister had taken the other one to her apartment), lay out some cardboard pieces on it, cut around them, bake the sheet, cut around the pieces one more time just after taking the sheet out of the oven, then punch them out after it cools. I got through 4 out of 6 before I needed to go to sleep - only a little bit behind schedule.
Day 2: Assembly

In the morning, I finished baking the rest of the pieces. I was going to see some cousins at a mall, so I popped into one of those fancy-looking mall candy stores to find materials for decorating. Everything was very expensive, and nothing was really right for a gingerbread house, but I grabbed some rock candy to try to melt into windows.
The whole window thing didn’t work out at all. As part of my anti-perfectionist Zen, I decided it would be better to finish it with mostly empty windows than to burn out.
After that, I mixed up a batch of this royal icing (I do not have many recipe sources in my life), and started putting it all together. I had made a cardboard support piece for the middle of the large hipped roof on the left, to put under it while the icing dried, but I realized as soon as I took it out that I’d need to bake a gingerbread piece or the roof would go down when I tried to decorate it. Other than that, it came together pretty easily: when the pieces didn’t line up quite right, I just slathered on more icing.
This day also ended a little behind schedule, with two roof pieces and a dormer not attached.
Day 3: Decoration
I glued on the remaining pieces, then got to work on the turret. I made a mold out of foil, but ended up mostly shaping it by hand. Rice Krispee treats are a totally gross invention. I had a couple of friends who were interested in decorating, so I mixed up some more icing but then sat back until they came over. Since I didn’t have a plan ready for decorating the thing, I just let my friends do whatever they thought would look good. The result was a little slapdash, but it made me really happy to be with people working on something like this.








Lessons Learned
- Nobody should ever try to make a gingerbread house in one day. Spread it out over at least two.
- Gingerbread can either taste good or be a good building material, but not both.
- Candy windows are extremely hard to do, and Ralph’s does not carry sheet gelatin. Order some online next time.
- It’s important to plan ahead with a big project, and lower your expectations. Things will happen that you didn’t plan for, so allow plenty of time.
- Finishing a creative project feels amazing, even if the result isn’t perfect.
